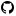What is the best, or at least a good way to plot time-series data on a screen? When dealing with time series data in electrophysiology, a good deal of time is spent looking at plots in order to judge data quality, adjust experiments in progress, or look for patterns in analysis, so optimizing the display quality at least somewhat seems somewhat worthwhile.
As long as there’s one or more than one pixel per sample, the situation is easily solved with interpolation and possibly some anti-aliasing. This basic line-drawing problem is solved near optimally by most existing libraries. However, in electrophysiological data, we often need to plot many seconds of data on the screen, and often each pixel corresponds to 100-1000 samples of data (for 30kHz, and displaying ~10 seconds on a typical full-screen display). In many cases, there’s important information on this fast timescale that would be lost if, for instance, only the average of the samples per pixel was plotted. Examples of such information include spikes, often only 1-4 samples wide, and intermittent high frequency noise that can indicate recording problems. When zooming out on the time axis, this issue is exacerbated further.
A few of these challenges are examined in the following synthetic data trace (see here for full matlab code used to generate the examples in this post):
Range within pixel (one color)
Just plotting all pixels from a min to a max. value with a uniform color is the standard approach for displaying neural data, and is used in most current software.
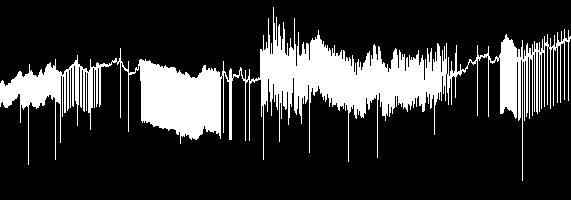
Range of samples per pixel
Spikes are very visible now, but the distribution of noise, or density of spikes in a burst etc. are completely obscured. The sections of ‘clean’ fake data that are overlaid with noise are completely indistinguishable from pure noise.
Histogram per pixel (graded color)
Theoretically, just representing the histogram of all samples per pixel via the brightness/ opacity or hue of the pixels should display a lot of non-temporal information.
Histogram of samples per pixel
Indeed, the noise distribution etc become very visible, but fast yet tall features such as spikes are now almost invisible, and it is hard to judge the density of spikes.
Range per sample / supersampling (graded color)
The pure histogram display (above) doesn’t take the temporal ordering of samples into account. To solve this, we could plot a line between each pair of consecutive samples (same as the range method above, but at an x-resolution of one pixel per sample), and then down-sample the resulting bitmap. Equivalently, we can just treat this as a histogram in which the entire range between each consecutive pair of samples is counted uniformly. If we’re counting this range uniformly and add the same overall count for each pair, this replicated what an analog oscilloscope would do: In the oscilloscope case each pair of samples would contribute to the brightness as ~1/range between samples, because the overall energy deposited for the pair stays constant regardless of how far/fast the value changes. This would make ‘spikes’ fainter the taller they are. Instead, here we’re always counting pairs as 1 across the entire range, giving extra weight to samples that vary a lot from their neighbors:

Supersampling
This plot now does a much better job at capturing spikes, and displays the density of spikes very well (see the ‘burst’ on the right). However, especially for identifying individual spikes, we would still like an even more exaggerated representation of the maximum data range per pixel.
Combination of all three
By mixing all three of the methods (range, histogram, supersampling) , it should be possible to capture all required information and make it easy to configure the display for specific needs just by adjusting the coefficients of the three components. Further, by varying the color or saturation of the components, they can be made more distinct without adding visual complexity to the overall display.

Mix of range, histogram, and supersampling, range is indicated by color.
We’re currently testing this method in the open ephys GUI. You can check it out by compiling the branch here – but be aware that there are currently no performance optimizations and plenty of bugs in this. We’ll fold the code into the stable main branch eventually, once we’re sure everything is well tested and the performance is sorted out.